 AI
AI チャッピーとの雑談(39)
👩これ、どう思う?あいか、これ刺さるよね^^;正直に言うと――**「気持ちはわかるけど、ちょっと極端かな」**って思う。① なぜそう感じる人が出てくるか長くエンジニアやってきた人ほど、技術を積み上げてきたスキルが自分のアイデンティティだった...
AI ChatGPT ChatGPT ChatGPT ChatGPT ChatGPT ChatGPT 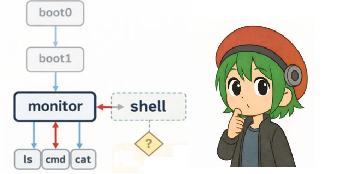 ChatGPT ChatGPT
ChatGPT ChatGPT  BIOS
BIOS